
Week of 2022-01-24

Behavior over time graphing tool
As I was writing last week’s bit on behavior over time graphs, I realized that I kind of want to have a simple tool that enables me to quickly draw and share a behavior over time graph. It seemed like a small-enough project. So I went ahead and wrote it. It is a picture of simplicity. Go to a page, adjust some points, type in a title and you’ve made your own visage of some behavior over time.
If you are using a computer with a mouse or touchpad, the adjustable points on the graph will reveal themselves as your cursor moves over the coordinate space. You can then drag any one of those points up or down. Click on the title at the top of the graph to edit and change it to your liking. If you are using a touch-based device (such as a phone or a tablet), just drag the curve with your finger.
Once you have your curve the way you want it and the title capturing its essence, click the “Share” button. This will change the URL to capture the parameters of the curve and its title. Now you can share your creation with your friends and colleagues or even complete strangers by sharing a URL. In most browsers, clicking the button will also copy the URL to the clipboard for convenience. Like this.
I am currently hosting the tool at https://dglazkov.github.io/botg/. Give it a whirl, and see if it works for you. If you encounter problems or have ideas for new features, file an issue here. Enjoy!
It was an interesting adventure. From the start, I wanted to go with something very simple and fast, so I opted against using dependencies or modern frontend stacks. I thought, hey – maybe I should try to code straight to the platform? After all, I was an Uber TL for the Chrome Web Platform team for a few years. Do I still have the chops?
Here’s what I’d found out. Custom elements are now everywhere. Shadow DOM just works. SVG works as intended, even though WebKit still has its repaint glitches (try to drag the curve and observe the “ripples” appearing on the dashed line in the center). Modules are amazing. Classes are amazing. The future had finally arrived. It is also all very well documented on MDN. It was kind of crazy to read about CSS variables as if they were just an ordinary part of the developer’s tool chest. How cool is that? I remember when we were pitching these ideas and people were looking at us like crazy. And – of course, OMG – VS Code. What an amazing development suite this project grew up to be.
All in all, a pleasant experience. However, here’s one thing I noticed. Even though I’d forgotten some names and keywords, I realized that the path I walked was informed by the intuition developed by working with the other side of the platform. Perhaps for those who haven’t spent years in the C++ entrails of the WebKit and Blink, coding directly to the platform might not be as easy?
🔗 https://glazkov.com/2022/01/26/behavior-over-time-graphing-tool/
Tracing the boundary
Early last year, I invested a bunch of time into exploring the idea of trustworthiness as it pertains to engineering products and people who use them. I found this to be an incredibly complex and nuanced topic, and I have learned a bunch of lenses and developed a few framings. I want to share one of these with you.
Let me preface the story with a bit of semantic disambiguation. When looking at trustworthiness, I am defining it from the perspective of a person interacting with a product. Let’s call them a “user” for simplicity, though I do have a few quibbles with that particular word (a digression for another time). So put simply, the degree of trustworthiness is the level to which a user considers the product worthy of their trust.
This definition unflinchingly hands the discernment of trustworthiness to my users. And, given that users are wonderfully diverse in their perspectives, it seems like the usefulness of applying such a framing is vanishingly small. After all, it is much easier to define trustworthiness in a principles-based approach, usually as a set of bright lines that I, the creator of the product, commit to never crossing. Once I have these principles outlined, I can organize processes and methodologies to ensure that they are satisfied.
The experience — however limited — from my exploration of the topic of trust is that even though a principle-based approach does offer a comfortable nest for us engineers and product managers to settle into, it is exceedingly difficult to get right. The trouble appears to stem from the fact that the bright lines are usually inferred from some idealized mental model of a user and thus rarely resemble trust-related concerns of the actual user. This feels like a general observation: principles are most effective when they are clear, yet clarity typically arises through removing the nuance. As a result, there’s a nagging sense of dissonance between my impassioned commitments to principles and the “meh” response of the users of my product.
I’ve been grappling with squaring this circle ever since, fairly unsuccessfully. One direction that seemed promising was the framing of boundaries and “tracing the boundary” thought experiment. Here is how it goes.
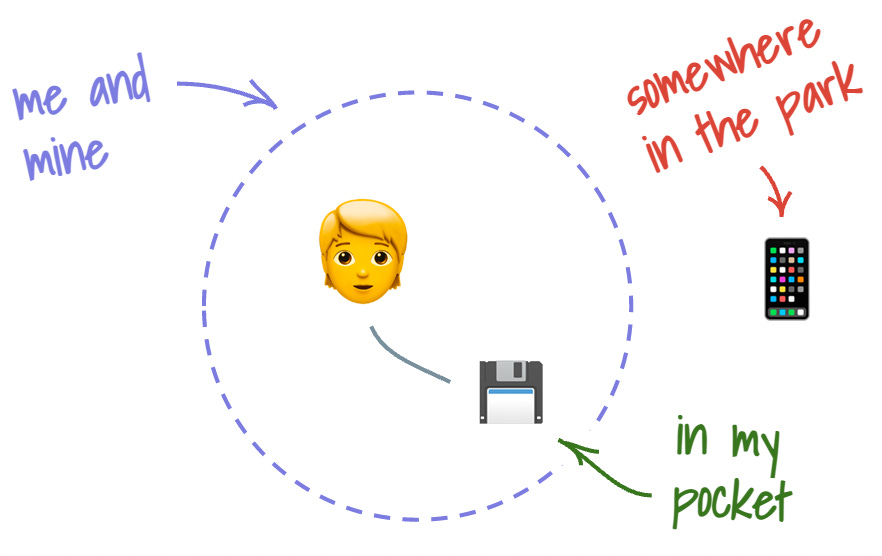
Imagine that every user is constantly and more or less unconsciously trying to trace the boundary around what’s theirs. Is it mine and if so, is it within or outside the boundary? If I have my phone in my front pocket, I feel like I can trace the boundary around this phone with confidence. At the same time, when I realize that I left this phone in the park, I no longer have such confidence. The phone now resides outside of the boundary, and given that this is my phone, I’d feel pretty anxious about it.
Similarly, when I have a piece of data stored on a — let’s go retro! — floppy disk, I know exactly where this data is stored. The disk becomes a physical embodiment of the data. I can now put it in my front pocket, or forget it at the park. In both cases, I will have clarity on whether my data is inside or outside my boundary.
As we start moving toward data that moves more or less frictionlessly across vast distances and in enormous quantities, the notion of a boundary becomes blurred. The task of tracing the boundary becomes more daunting and seemingly impossible. I have to contend with the idea that I can’t confidently draw boundaries around things I consider mine. And in many cases, I can’t account for all the things out there that if I knew they existed, I would consider mine.
My sense is that the trustworthiness of a product is somehow correlated with the degree to which the user believes they can trace the boundary around what’s theirs. If as a user, I have high confidence that I know how everything of mine is kept by the product — be that inside or outside my traced boundary, — I can develop a trusting relationship with this product. If, on the other hand, I have low confidence of understanding how things of mine are handled, I am unlikely to find this product trustworthy.
Now, my confidence may be misplaced. My mental model of how the product keeps what’s mine could be naively optimistic – or conversely, overly paranoid. My intuition is that it is the trustworthiness, the predilection to having a relationship with the product is what enables me, the user, to develop a more accurate mental model over time. And in this thought experiment, I do it by tracing and retracing the boundaries of what’s me and mine.