
Week of 2022-09-12

Where I ponder strategies that drive ideas and innovation, as well as invent a new metric for innovation potential. Very innovative of me.
r/K selection and innovation
I’ve been thinking about the different conditions under which innovation emerges, and how the environment influences the kind of innovation that happens.
To set the stage, I am going to do a very brief detour into biology (I am not a biologist, so will definitely make a mess of it) and use the r/K-selection lens to guide this story. If we observe various organisms, the theory goes that all fall somewhere in the spectrum between r-selection and K-selection. The r-selection is a strategy that’s focused on reproduction: make copies of my kind as quickly as possible, and mutate generation to generation. The K-selection is a carrying capacity strategy: stay alive as long as possible, learn and teach my (usually very few) offsprings the necessary tricks to thrive. Both are viable strategies, depending on the environment.
Typical examples used for r-selection are dandelions and for K-selection – elephants. To bring it closer to home, we can have coronavirus represent the side of the r-selection, and us humans the K-selection. The battle of pandemic/endemic we’re still locked in shows that humans are likely to win, but oh boy is COVID giving us the run for the money.
Turning to the realm of ideas, it seems that some of them are r-selected. In the most basic form, ideas are memes: easily transmitted, rapidly spreading earworms. Each transmission is an opportunity for mutation. As they inhabit our mind, ideas fall in the fertile ground of other ideas and the next time we communicate these ideas, we – nearly always – change them. They mutate into something different. As the r-selected strategy suggests, ideas evolve as they are copied.
Other kinds of ideas are K-selected. These are usually larger, self-coherent entanglements of smaller ideas. They live in our minds and they evolve over time, growing and maturing. Just like K-selected organisms, thes ideas reproduce with pain and effort. We can’t just give them to others. We must garner our patience and engage with them in the process of teaching, smuggling them across the often unreliable medium of interpersonal communication, one tiny elemental bit at a time.
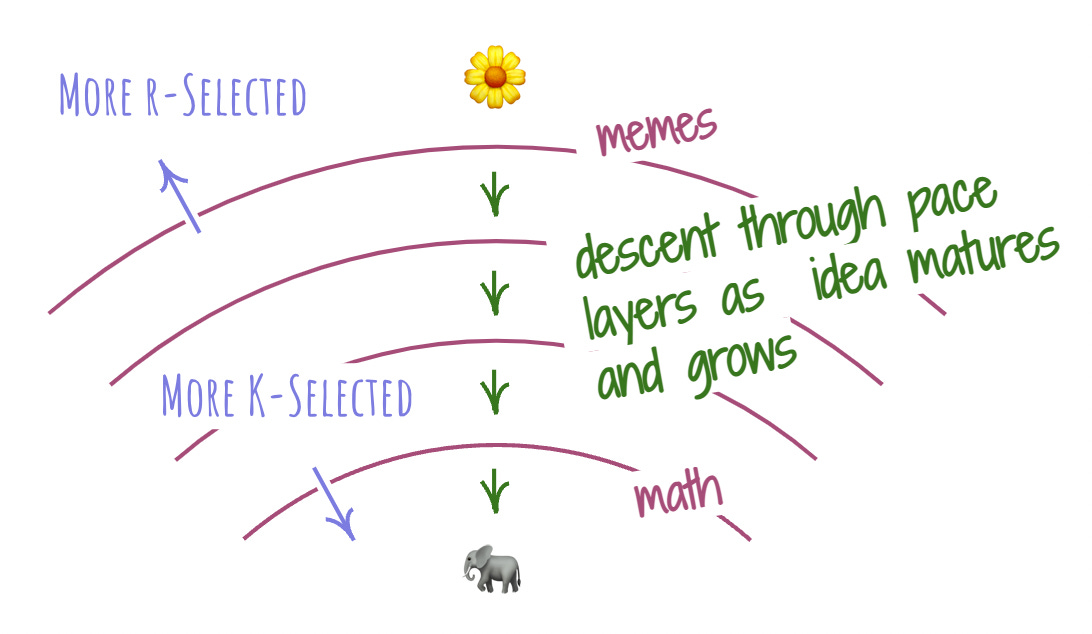
My fellow FLUX-er Erika pointed out that by putting these two strategies into a spectrum, a framing of pace layers pops out. There are simple ideas boiling afroth at the top layer in a pure r-selected strategy. As they connect with other ideas, their strategy becomes more and more K-selection-like, forming layers that move at a slower pace. Learning Newtonian physics? Welcome to the lower layers. Reading the latest memes on Twitter? That’s at the top.
This pace layering offers us a neat way to look at the kinds of innovation. Since innovation is powered by ideas, we can see it manifest in different ways at different pace layers. The higher, more r-selected layers are great for rapidly exploring new spaces, where there are lots of unknowns and possibilities. The lower, more K-selected layers are incredibly effective for optimizing and refining existing ideas. As ideas mature, they traverse the pace layers, descending from r to K.
Using this lens, an organization that desires to innovate can act more intentionally by picking the idea selection strategy. If we’re looking at a new wide-open space, or searching for the next frontier, we would want to create conditions where ideas can spread rapidly and replicate to mutate.
A recent example of this happening is the release of Stable Diffusion, an AI model for generating images from prompts. Simon Willison has an insightful write-up of the phenomenon, and we don’t have to squint to spot application of the r-selected strategy: the model and the surrounding tools are open source, and the process of setting up your own instance is fairly straightforward.
Combined with rising interest around the future potential of generative media, this caused an immediate explosion of innovation: people messing with it for fun and/or quickly putting together possible business ideas. Given that no other contenders offered such an opportunity to the interested crowd, I would not at all be surprised if Stable Diffusion, no matter how well it fares in its comparative quality today, becomes the de-facto engine for generating pictures from text.
On the other hand, if we want to climb the gradient hill and improve upon an existing idea, we are better off picking the K-selected strategy: invest into apprenticeship practices to facilitate tacit knowledge transfer, and ensure that idea refinements are carefully curated.
I will once again lean onto browser development to illustrate the K-selected strategy. The modern Web rendering engine, which is the thing that interprets text, images, and code as a visual, interactive composition on your screen that we call “Web sites” is a prototypical outcome of descending down the pace layers.
A wild-haired idea at first, it eventually grew into a massively complicated and often self-contradictory tangle of ideas that is captured in code. There are only three distinct instances of that code: WebKit, Blink, and Gecko. These instances try to interoperate, and there is an incredible amount of knowledge — both tacit and described in long, dry documents called specs – that need to be grokked before proceeding with constructing another instance. If Stable Diffusion is a dandelion, Web rendering engines are elephants.
One does not simply create a new rendering engine. To move forward, a K-selected strategy is called for. When we look at the efforts surrounding creating a rendering engine, we can see extensive documentation and education that helps aspiring Web browser engineers climb the learning curve, as well as rigorous processes to ensure that every change that is being made to the codebase carefully, yet purposefully evolves the project.
Similarly, we can anticipate mismatches in the kind of innovation we’d like to see and the strategy that we have at our disposal. We can’t expect to explore a new space with data-driven analyses and an elite team of experts — just like we can’t expect to see consistent results aimed toward some goal if we’re set up for rapid, unbridled experimentation.
🔗 https://glazkov.com/2022/09/15/r-k-selection-and-innovation/
e-LOC
I’d like to introduce a metric for developer APIs that I call “e-LOC”. I am not great with names, so it’ll just have to wait until someone gives it a better one. Meanwhile, let’s explore it.
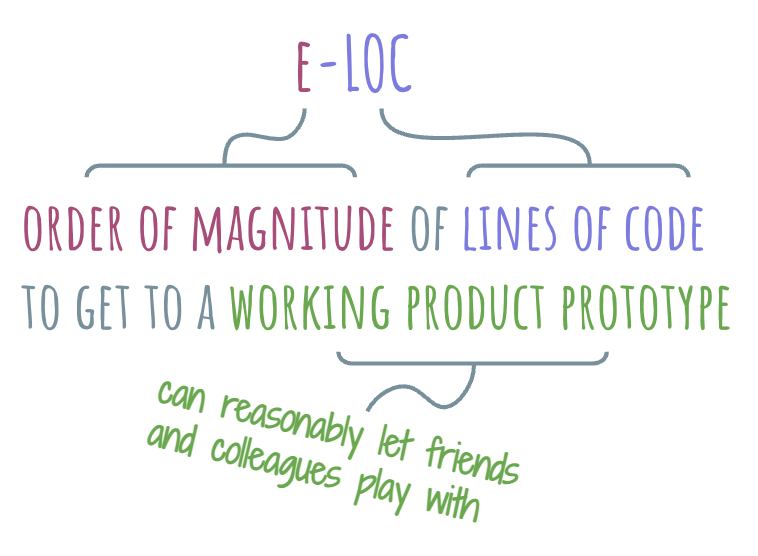
The definition of e-LOC is as follows: e-LOC of a technology is the order of magnitude of lines of code that one needs to write to get to a working product prototype using this technology. Applying the usual metric prefixes, we get ourselves a nice scale: 0-LOC, deca-LOC, hecto-LOC, kilo-LOC, mega-LOC, and so on.
Various APIs reside on different parts of this scale. A finished, functioning product is 0-LOC. On the other side of the scale is a developer surface that requires gazillon of lines of code to produce something that we can reasonably offer to our friends and colleagues to try out. Want to build a web-based product prototype? It’s probably going to be hecta-LOC. A brand new Web rendering engine? You’re likely looking at a mega-LOC.
The order of magnitude serves as a decent measure of developer barrier to entry. For a deca-LOC, it’s just a handful of lines of code, so the barrier is very low. For Web rendering engines, only a skilled, determined, and well-funded team of developers can overcome it.
Because of this barrier to entry property, the e-LOC can serve as a leading indicator for the amount of innovation that will happen around a given technology. Put differently, e-LOC can be used to measure innovation potential of a technology.
New OSes and rendering engines are one-shot, single-lane affairs. They undoubtedly innovate, but the fruits of this innovation are singular and rare. On the other side of the scale, if it takes 60 lines to make a working Discord bot that generates pictures using Stable Diffusion, nearly anyone can do it. Expect a lot of people to be messing around with these APIs and trying to build something interesting with them.
Another useful property of e-LOC is that it also indicates how much opinion is contained within the API or technology. More opinionated APIs will tend to have lower e-LOC, while the less opinionated ones will trend higher in numbers. Of course, lower e-LOC doesn’t make the API good. That’s not what this metric measures. Some of the most troublesome, gnarly APIs are deca-LOCs.
The opposing directions of opinion and developer barrier to entry present an interesting tension in innovation potential. A 0-LOC technology is fully opinionated and requires zero lines to use. Because of that, it also has zero innovation potential. The innovation potential increases proportionally to the amount of opinion that could still be added, yet the barrier to development tapers it off as the e-LOC scale increases.
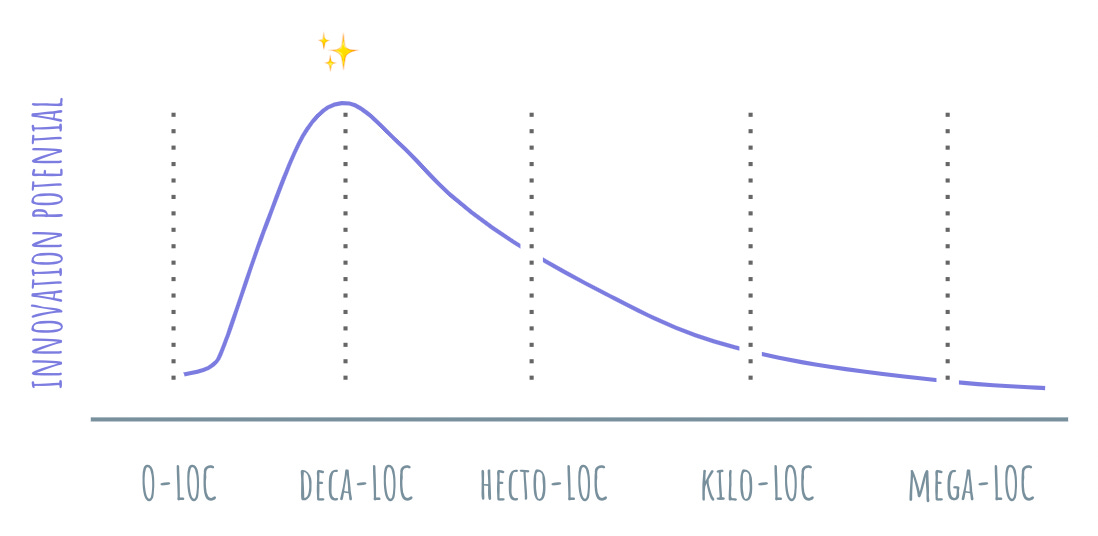
Advancing the state of my earlier developer funnel framing, we can draw this as a curve to illustrate the relationship of technology innovation potential and e-LOC. The curve starts at near-zero at the beginning of the scale, then rapidly expands to its maximum value at around deca- and hecto-LOC, then drops off in a power law fashion as the magnitude of lines of code keeps increasing. The near-zero at the start is significant: in my experience, even finished products end up growing APIs, whether they want it or not.
This metric gives us a nice way to orient our thinking around the purpose of the technology we might be building. How much innovation do we want it to spur? If we want to minimize it, we ship only finished products. If we want to maximize it, we must relentlessly drive our APIs to be in deca-LOC range.
This was great - and I like the r/K framework a lot. It seems to me that it would be interesting to also figure out how they relate to each-other: when everyone else is in K, r could potentially be more successful and vice versa. A bit like Donna Tartt's "one-book-every-decade" in a world that blogs every day. That generally suggests that there is such a thing as a pace strategy given where the average is - either relatively slow or relatively fast gives an advantage. I also think that r-strategies tend to work better under high selection pressures - because then an r-strategy can search more quickly and explore the fitness landscape. Under lower selection pressures a K strategy mitigates the risk of evolutionary drift presented by r-strategies - maybe. Another way to conceptualise this is to think about competitive strategy as composed by two dimensions: adaptation to the environment and adaptation to others in the environment. The mix you pick will matter - if you are 80/20 for environment / others and have a really good sense of where the environment is headed you may build a greater competitive advantage. Most companies tend to be 20/80, however, overly focused on the competition rather than the environment. Any decent strategic analysis should probably have one section for the environment and one for competitors and then suggest a mixed portfolio strategy. Inspiring post!
Very interesting thoughts! I had a similar metaphorical thought this morning after waking up but the direction was in reverse :)
That stable diffusion thing....wow :D