
Week of 2023-04-17

Where I describe the concept of reasoning boxes and predict the next revolution in AI – LOL kidding! …Or am I? And also introduce the “porcelains” pattern for that extra-sanitary developer experience.
Reasoning boxes
This story begins with the introduction of metacognition to large language models (LLMs). In the LLM days of yore (like a few months ago), we just saw them as things we could ask questions and get answers back. It was exciting. People wrote think pieces about the future of AI and all that jazz.
But then a few extra-curious folks (this is the paper that opened my eyes) realized that you could do something slightly different: instead of asking for an answer, we could ask for the reasoning that might lead to the answer.
Instead of “where do I buy comfortable shoes my size?”, we could inquire: “hey, I am going to give you a question, but don’t answer it. Instead, tell me how you would reason about arriving at the answer. Oh, and give me the list of steps that would lead to finding the answer. Here’s the question: where do I buy comfortable shoes my size?”
Do you sense the shift? It’s like an instant leveling up, the reshaping of the landscape. Instead of remaining hidden in the nethers of the model, the reasoning about the question is now out in the open. We can look at this reasoning and do what we would do with any reasoning that’s legible to us: examine it for inconsistencies and decide for ourselves if this reasoning and the steps supplied will indeed lead us toward the answer. Such legibility of reasoning is a powerful thing.
With reasoning becoming observable, we iterate to constrain and shape it. We could tell the LLM to only use specific actions of our choice as steps in the reasoning. We could also specify particular means of reasoning to use, like taking multiple perspectives or providing a collection of lenses to rely on.
To kick it up another notch, we could ask an LLM to reason about its own reasoning. We could ask it “Alright, you came up with these steps to answer this question. What do you think? Will these work? What’s missing?” As long as we request to provide the reasoning back, we are still in the metacognitive territory.
We could also give it the outcomes of some of the actions it suggested as part of the original reasoning and ask it to reason about these outcomes. We could specify that we tried one of the steps and it didn’t work. Or maybe that it worked, but made it impossible for us to go to the next step – and ask it to reason about that.
From the question-answering box, we’ve upleveled to the reasoning box.
All reasoning boxes I’ve noticed appear to have this common structure. A reasoning box has three inputs: context, problem, and framing. The output is the actual reasoning.

The context is the important information that we believe the box needs to have to reason. It could be the list of the tools we would like it to use for reasoning, the log of prior attempts at reasoning (aka memory), information produced by these previous attempts at reasoning, or any other significant stuff that helps the reasoning process.
The problem is the actual question or statement that we would like our box to reason about. It could be something like the shoe-shopper question above, or anything else we would want to reason about, from code to philosophical dilemmas.
The final input is the framing. The reasoning box needs rails on which to reason, and the framing provides these rails. This is currently the domain of prompt engineering, where we discern resonant cues in the massive epistemological tangle that is LLM that give to the reasoning box the perspective we’re looking for. It usually goes like “You are a friendly bot that …” or “Your task is to…”. Framing is sort of like a mind-seed for the reasoning box, defining the kind of reasoning output it will provide.
Given that most of the time we would want to examine the reasoning in some organized way, the framing usually also constrains the output to be easily parsed, be it a simple list, CSV, or JSON.
A reasoning box is certainly a neat device. But by itself, it’s just a fun little project. What makes reasoning boxes useful is connecting them to ground truth. Once we connect a reasoning box to a ground truth, we get the real sparkles. Ground truth gives us a way to build a feedback loop.
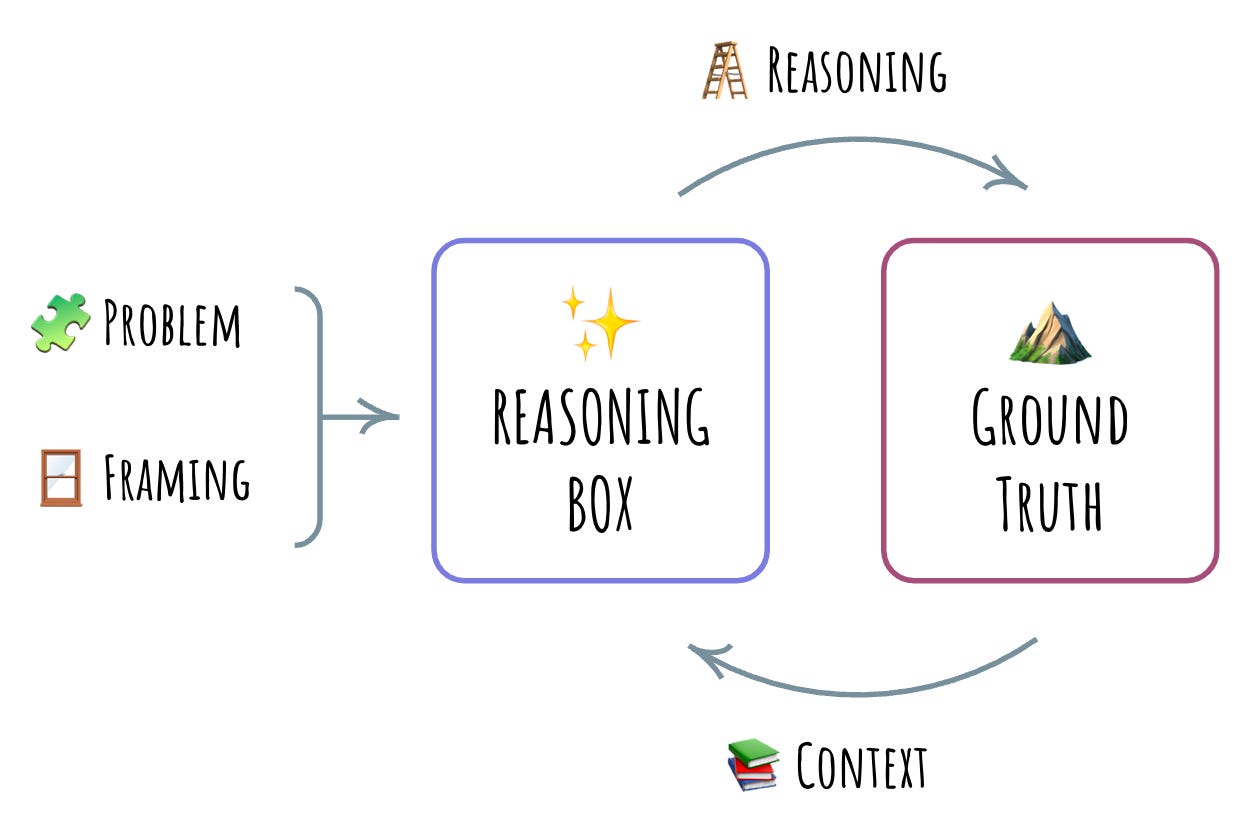
What is this ground truth? Well, it’s anything that can inform the reasoning box about the outcomes of its reasoning. For example, in our shoe example, a ground truth could be us informing the box of the successes or failures of actions the reasoning box supplied as part of its reasoning.
If we look at it as a device, a ground truth takes one input and produces one output. The input is the reasoning and the output is the outcomes of applying this reasoning. I am very careful not to call ground truth “the ground truth”, because what truths are significant may vary depending on the kinds of reasoning we seek.
For example, and as I implied earlier, a reasoning box itself is a perfectly acceptable ground truthing device. In other words, we could connect two reasoning boxes together, feeding one’s output into another’s context – and see what happens. That’s the basics of the structure behind AutoGPT.
Connecting a reasoning box to a real-life ground truth is what most AI Agents are. They are reasoning boxes whose reasoning is used by a ground truthing device to take actions, like searching the web or querying data sources – and then feeding the outcomes of these actions back into the reasoning boxes. The ground truth connection is what gives reasoning boxes agency.
And I wonder if there’s more to this story?
My intuition is that that the reasoning box and a ground truthing device are the two kinds of blocks we need to build what I call “socratic machines”: networks of reasoning boxes and ground truthing devices that are capable of independently producing self-consistent reasoning. That is, we can now build machines that can observe things around them, hypothesize, and despite all of the hallucinations that they may occasionally incur, arrive at well-reasoned conclusions about them.
The quality of these conclusions will depend very much on the type of ground truthing these machines have and the kind of framing they are equipped with. My guess is that socratic machines might even be able to detect ground truthing inconsistencies by reasoning about them, kind of like how our own minds are able to create the illusion of clear vision despite only receiving a bunch of semi-random blobs that our visual organs supply. And similarly, they might be able to discern, repair and enrich insufficient framings, similar to how our minds undergo vertical development.
This all sounds outlandish even to me, and I can already spot some asymptotes that this whole mess may bump into. However, it is already pretty clear that we are moving past the age of chatbots and into the age of reasoning boxes. Who knows, maybe the age of socratic machines is next to come?
🔗 https://glazkov.com/2023/04/20/reasoning-boxes/
Porcelains
My friend Dion asked me to write this down. It's a neat little pattern that I just recently uncovered, and it’s been delighting me for the last couple of days. I named it “porcelains”, partially as an homage to spiritually similar git porcelains, partially because I just love the darned word. Porcelains! ✨ So sparkly.
The pattern goes like this. When we build our own cool thing on top of an existing developer surface, we nearly always do the wrapping thing: we take the layer that we’re building on top and wrap our code around it. In doing so, we immediately create another, higher layer. Now, the consumers of our thing are one layer up from the layer from which we started. This wrapping move is very intuitive and something that I used to do without thinking.
// my API which wraps over the underlying layer.
const callMyCoolService = async (payload) => {
const myCoolServiceUrl = "example.com/mycoolservice";
return await // the underlying layer that I wrap: `fetch`
(
await fetch(url, {
method: "POST",
body: JSON.stringify(payload),
})
).json();
};
// ...
// at the consuming call site:
const result = await callMyCoolService({ foo: "bar" });
console.log(result);However, as a result of creating this layer, I now become responsible for a bunch of things. First, I need to ensure that the layer doesn’t have too much opinion and doesn’t accrue its cost for developers. Second, I need to ensure that the layer doesn’t have gaps. Third, I need to carefully navigate the cheesecake or baklava tension and be cognizant of the layer thickness. All of a sudden, I am burdened with all of the concerns of the layer maintainer.
It’s alright if that’s what I am setting out to do. But if I just want to add some utility to an existing layer, this feels like way too much. How might we lower this burden?
This is where porcelains come in. The porcelain pattern refers to only adding code to supplement the lower layer functionality, rather than wrapping it in a new layer. It’s kind of like – instead of adding new plumbing, put a purpose-designed porcelain fixture next to it.
Consider the code snippet above. The fetch API is pretty comprehensive and – let’s admit it – elegantly designed API. It comes with all kinds of bells and whistles, from signaling to streaming support. So why wrap it?
What if instead, we write our code like this:
// my API which only supplies a well-formatted Request.
const myCoolServiceRequest = (payload) =>
Request("example.com/mycoolservice", {
method: "POST",
body: JSON.stringify(payload),
});
// ...
// at the consuming call site:
const result = await (
await fetch(myCoolServiceRequest({ foo: "bar" }))
).json();
console.log(result);Sure, the call site is a bit more verbose, but check this out: we are now very clear what underlying API is being used and how. There is no doubt that fetch is being used. And our linter will tell us if we’re using it improperly.
We have more flexibility in how the results of the API could be consumed. For example, if I don’t actually want to parse the text of the API (like, if I just want to turn around and send it along to another endpoint), I don’t have to re-parse it.
Instead of adding a new layer of plumbing, we just installed a porcelain that makes it more shiny for a particular use case.
Because they don’t call into the lower layer, porcelains are a lot more testable. The snippet above is very easy to interrogate for validity, without having to mock/fake the server endpoint. And we know that fetch will do its job well (we’re all in big trouble otherwise).
There’s also a really fun mix-and-match quality to porcelain. For instance, if I want to add support for streaming responses to my service, I don’t need to create a separate endpoint or have tortured optional arguments. I just roll out a different porcelain:
// Same porcelain as above.
const myCoolServiceRequest = (payload) =>
Request("example.com/mycoolservice", {
method: "POST",
body: JSON.stringify(payload),
});
// New streaming porcelain.
class MyServiceStreamer {
writable;
readable;
// TODO: Implement this porcelain.
}
// ...
// at the consuming call site:
const result = await fetch(
myCoolServiceRequest({ foo: "bar", streaming: true })
).body.pipeThrough(new MyServiceStreamer());
for await (const chunk of result) {
process.stdout.write(chunk);
}
process.stdout.write("\n");I am using all of the standard Fetch API plumbing – except with my shiny porcelains, they are now specialized to my needs.
The biggest con of the porcelain pattern is that the plumbing is now exposed: all the bits that we typically tuck so neatly under succinct and elegant API call signatures are kind of hanging out.
This might put some API designers off. I completely understand. I’ve been of the same persuasion for a while. It’s just that I’ve seen the users of my simple APIs spend a bunch of time prying those beautiful covers and tiles open just to get to do something I didn’t expect them to do. So maybe exposed plumbing is a feature, not a bug?