
Week of 2023-04-24

Where I talk about a technique to help engineering teams explore new spaces and explore LLMs some more with the concept miner.
Separating cargo from the train
I’ve been puzzling over a problem that many engineering teams face and came up with this metaphor. It’s situated in the general space of attachment and could probably apply to things other than engineering teams.
Here’s the setup. Imagine that we’re leading a team whose objective is to rapidly explore some newly opened space. Everyone gets their little area of the space, and armed with enthusiasm and skill, the teams venture off into the unknown. A few months later, a weird thing happens: now we have N teams that build technology or products in basically the same space where they started.
Instead of exploring, the team just settled into the first interesting thing they found. Exploration collapsed into optimizing for the newly found value niche.
This might not necessarily be a bad thing. If the new space is ripe with opportunities or the team is incredibly lucky, they might have struck gold on the first try. Except my experience tells me that most of the time, the full value of the niche is grossly overestimated, and the teams end up organizing themselves into settlers of a tiny “meh” value space.
The events that follow are fairly predictable. There is a struggle between us and the individual team leads to “align”, where the word “align” really stands for “what the heck are y’all doing?! we were supposed to be exploring!!” from us and “stop distracting us with your silly ideas! we have customers to serve and things to ship!” from the sub-teams. The team becomes stuck.
I have seen various ways in which the resolution plays out. There’s one with the uneasy compromise, where the “exploration team” kayfabe is played out at the higher levels (mostly in slide decks), and the sub-teams are just left to do their thing. There’s one with the leader making a “quake”: a swift reorg that leaves the sub-team leads without a path forward. There’s one where a new stealth sub-team is started to actually explore (you can guess what happens next).
The lens that really helps here is “something will get optimized”. When we have engineers, we have people whose literal job description includes organizing code into something that lasts. Like a car with unbalanced wheels, by default, engineers will veer toward elephant-land. Given no other optimization criteria, what will get optimized is the quality of the code base and the robustness of the technical solution that it offers.
The problem is, when exploring, we don’t need any of that. We need messy, crappy code that somewhat works to get a good sense of whether there’s a there there. And then we need to throw that code out or leave it as-is and move on to the next part of the space.
This is not at all natural and intuitive for engineering teams. There are no tests! Not even a code review process! This dependency was made by a random person in Nebraska! Madness!
By the way, the opposite of this phenomenon is also true. If our engineering team does not have this tendency toward building code that lasts, we probably don’t have an engineering team. We might have some coders or programmers, but no engineering.
To shift an engineering team to be more amenable to exploration, we need to shift the target of the optimization.
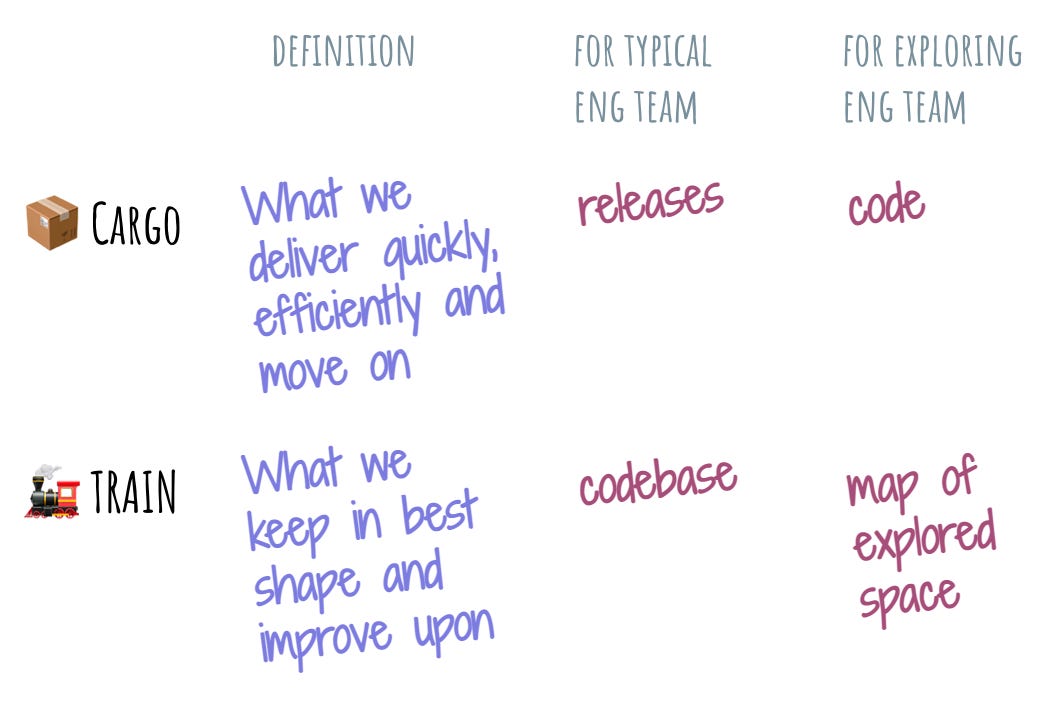
That’s where the cargo-and-train metaphor comes in. Let’s pretend that an engineering team is the train that delivers a cargo: a thing that it makes. The thing about cargo is that once it is delivered, it leaves the train and the train gets new cargo. Train is permanent. Cargo is transient.
To make our train go efficiently, we optimize for moving cargo as quickly as possible, and we optimize for keeping the train in its best condition. Figuring out which part of our work we optimize to keep and which one we optimize to move is what it’s all about.
If we follow this metaphor, there are two questions that an engineering team needs to ask itself: “What is our cargo?” and “What is our train?” We need to consciously separate our cargo from our train.
Which part of our business do we optimize to let go of as efficiently as possible, and which part of it do we keep and grow?
For a typical engineering team, the cargo is the software release and the code base is the train.
Each release is the snapshot of the code base at a certain state. Once that release cut is made, we mentally let go of it and start on the next release. Releasing well means being able to make a release cut like a Swiss train: always on time, with no hiccups.
The codebase is the train, since this is where releases come from. Codebase is the place where the product grows and matures. Our codebase is what we keep and improve and strive to make better with time. Terms like technical debt we engineers invent reflect our anxiety about succeeding at this process.
When the engineering team is asked to explore a new space, the answers to the two questions are like different.
It might very well be that the code we write is cargo. It’s just something we do as a byproduct of our exploration. We write a ton of prototypes, throw them in the wild, and see which ones stick.
What is the train then? My intuition is that it’s knowledge. After all, the whole point of exploration is mapping the unknown. If our continuous delivery of cargo – writing of prototypes – doesn’t light up more and more territory, we’re doing something wrong.
So when an engineering team is asked to explore a new space, we need to contemplate the cargo-and-train questions carefully and decide on our answers to them.
Then, we need to invest into making sure that everyone on the team optimizes for the right thing: the thing that we want to be our cargo is optimized to be delivered and let go of quickly, and the thing we want to be our train is carefully and lovingly grown and enriched with each delivery.
This includes everything from mission and vision where the cargo-and-train questions are clearly answered, but also into culture, incentives, and structure of the team. Remember – most of the default engineering practices and processes were designed for default engineering teams. Which means that if we’re setting out to explore, they will be working against us.
🔗 https://glazkov.com/2023/04/23/separating-cargo-from-the-train/
Concept miner
Here’s a concrete example of a reasoning box that I’ve been talking about last week. It’s not super-flashy or cool – certainly not one of those viral demos, but it’s a useful example of recursively ground-truthing a reasoning box onto itself. The source code is here if you want to run it yourself.
The initial idea I wanted to play with was concept extraction: taking a few text passages and then turning them into a graph of interesting concepts that are present in the text. The vertices of the graph would be the concepts and the edges will represent the logical connections between them.
I started with a fairly simple prompt:
Analyze the text and identify all core concepts defined within the text and connections between them.
Represent the mental concept and connections between them as JSON in the following format:
{
"concept name": {
"definition": "brief definition of the concept",
"connections": [ a list of of concept names that connect with this concept ]
}
}
TEXT TO ANALYZE:
${input}
This is mostly a typical reasoning box – take in some framing, context, and a problem statement (“identify all core concepts”), and produce a structured output that reflects the reasoning. In this particular case, I am not asking for the chain of reasoning, but rather for a network of reasoning.
The initial output was nice, but clearly incomplete. So I thought – hey, what if I feed the output back into the LLM, but with a different prompt. In this prompt, I would ask it to refine the list of concepts:
Analyze the text and identify all core concepts defined within the text and connections between them.
Represent the mental concept and connections between them as JSON in the following format:
{
"concept name": {
"definition": "brief definition of the concept",
"connections": [ a list of of concept names that connect with this concept ]
}
}
TEXT TO ANALYZE:
${input}
RESPONSE:
${concepts}
Identify all additional concepts from the provided text that are not yet in the JSON response and incorporate them into the JSON response. Add only concepts that are directly mentioned in the text. Remove concepts that were not mentioned in the text.
Reply with the updated JSON response.
RESPONSE:
Notice what is happening here. I am not only asking the reasoning box to identify the concepts. I am also providing the outcome of its previous reasoning and asking to assess the quality of this reasoning.
Turns out, this is enough to spur a ground truth response in the reasoning box: when I run it recursively, the list of concepts grows and concept definitions get refined, while connections shift around to better represent the graph. I might start with five or six concepts in the first run, and then expand into a dozen or more. Each successive run improves the state of the concept graph.
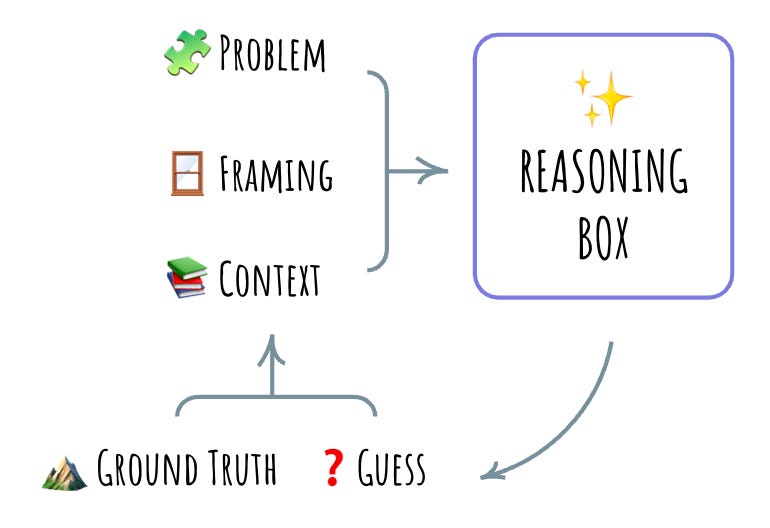
This is somewhat different from the common agent pattern in reasoning boxes, where the outcomes of agent’s actions serve as the ground truth. Instead, the ground truth is static – it’s the original text passages, and it is the previous response that is reasoned about. Think of it as the reasoning box making guesses against some ground truth that needs to be puzzled out and then repeatedly evaluating these guesses. Each new guess is based on the previous guess – it’s a path-dependent reasoning.
Eventually, when the graph settles down and no more changes are introduced, the reasoning box produces a fairly well-reasoned representation of a text passage as a graph of concepts.
We could maybe incorporate it into our writing process, and use it to see if the concepts in our writing connect in the way we desire, and if the definitions of these concepts are discernible. Because the reasoning box has no additional context, what we’ll see in the concept graph can serve as a good way to gauge if our writing will make sense to others.
We could maybe create multiple graphs for multiple passages and see if similar concepts emerge – and how they might connect. Or maybe use it to spot text written in a way that is not coherent and the concepts are either not well-formed or too thinly connected.
Or we could just marvel at the fact that just a few lines of code and two prompts give us something that was largely inaccessible just a year ago. Dandelions FTW.