
Week of 2023-05-01

Where I explore the limits of applying large language models and also introduce the idea of a waterline: a line of optimal effectiveness that each company has and is nudged toward.
Limits of applying AI
I’ve been thinking about the boundaries of what’s possible when applying large language models (LLMs) to various domains. Here’s a framing that might not be fully cooked, but probably worth sharing. Help me make it better.
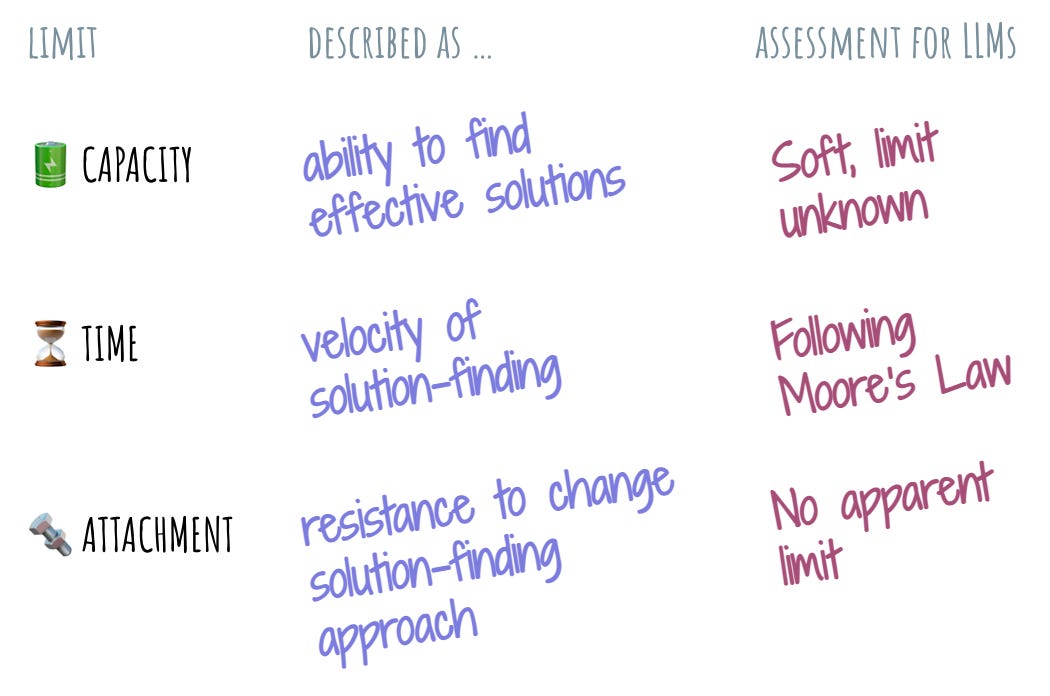
To set things up, I will use the limits lens from the problem understanding framework. Roughly, I identify three key limits that bound what’s possible for anyone who is put in front of a problem: capacity, or the actual ability to find effective solutions (one or more) to the problem; time, the velocity at which effective solutions are discovered; and finally, attachment, or the resistance to incorporate interesting information into their understanding of the problem to find solutions.
These three limits govern what we humans can do. Let’s see how these limits could be applied to LLMs.
Let me start with capacity. The fact that this limit applies to LLMs is fairly self-evident, and can be illustrated easily with the progress we have made in the last year. What was impossible just 18 months ago is now a widely accepted capability. The progression to larger models, larger context windows feels like a constant drumbeat – this is the capacity limit being pushed further and further back. When will we run into the wall of the invisible asymptote? When will we be able to confidently say: “Aha! Here’s proof that LLMs can’t actually do that”? It’s not easy to tell. However, just like with all things of this world, this limit is still present with LLMs. We just haven’t quite found it yet.
Another interesting trick that LLMs have compared to humans is the ability to clone. A bot or an agent or a network of reasoning are easily reproducible. One does not need to spend a lifetime raising an LLM from infant to adulthood. Once a pattern is established, clones of this pattern are easy to produce. This is a significant source of capacity. Being more numerous is easy, which means that brute force can compensate for smarts in a pinch.
The final component of the limit of capacity is the computing power. The amount of energy it takes to make the LLM produce a potential answer to a given problem seems like an important factor. Again, we seem to be marching along the Moore’s Law curve here, and I expect each new breakthrough in atoms and bits to significantly push the capacity limit out.
Speaking of the future, let’s talk about the limit of time. I sprinkled the references to time into my examination of the limit of capacity. They seem closely interrelated. LLMs becoming more capable and efficient means that they will also be able to solve problems more effectively. At this moment of time, I am contemplating networks of reasoning boxes, which implies the era when invoking LLMs will take single milliseconds. This seems to fall out naturally of the limit of capacity advancing. There will likely be an asymptote we’ll hit with how fast an LLM can go, but we’re definitely not there yet.
The limit of attachment is the one that’s been most curious for me. As far as I can tell, LLMs don’t seem to have it at all. While people could get bored or tired, or have anxiety about doing things one way or another, express strong convictions and make rash decisions… LLMs don’t seem to have any of that. LLMs don’t have the “ooh, I wonder what <character> will do next on <TV show> episode“ mindworm. They don’t need to rush home to put their kid to bed. They have no desire to spend the day just hanging out with friends. LLMs are unattached. There is no inner shame that they have to protect at all cost. There are no values that they passionately embrace. The limit of attachment for LLMs appears to be a bottomless abyss – or a blue sky, if you’re into more positive metaphors.
Will the limit of attachment manifest itself for LLMs? Probably. There’s something very significant about this lack of the limit that indicates the vastness of the space we’re in.
So, what does this mean in practice?
As I was saying to my colleagues, we’re at the 8-track tape stage of the whole LLM story. What we think is cool and amazing now will be viewed as silly and as quaint as the 8-track tapes just a few months in the future. Prepare for more tectonic shifts as the previously understood lines of the capacity limit are redrawn. Avoid early firm bets on the final shape of things in this space.
Also, we’re likely very close to the moment when we will have a decent representation of an “information worker”, probably as some sort of reasoning network. This worker will never get tired, will never complain about the problem being too pedestrian for their talents, will never slack off or quiet-quit. This worker will continuously improve and get better at the tasks that they are given, performing them more efficiently each time.
Looking at the LLM bounding box – or more accurately, the lack thereof – my intuition is that we’re going to see terraforming of entire industries, especially where information plumbing is a significant cost of doing business. I have no idea how they will change and what they will look like after the dust settles, but it’s very likely that this change will happen.
More importantly, as this change grinds into our established understanding of how things are, we are likely to grapple with it as a society. It is very possible that it is our own limits of attachment that we will try to impose on the LLMs, no matter how fruitless this effort will end up being in the long term.
🔗 https://glazkov.com/2023/04/29/limits-of-applying-ai/
The waterline
This one is a very short framing, but hopefully, it’s still useful. Whenever we operate in environments that look like pace layers (and when don’t they?), there emerges a question of relative velocity. How fast am I moving relative to the pace layer where I want to play?

If the environment that surrounds us is moving slower than our team’s velocity, we will feel overly constrained and frustrated. Doing anything appears to be laden with unnecessary friction. On the other hand, if the environment is moving faster than us, we’ll feel like a tractor on an autobahn: everyone is zooming past us. Whenever something like this happens, this means that our relative velocity doesn’t match the velocity of the pace layer in which we’ve chosen to play.
This mismatch will feel uncomfortable, and there is a force hiding behind this discomfort. This force will constantly nudge us toward the appropriate layer.
If, after working in a startup where writing hacky code and getting it out to customers quickly was existential, I join a well-structured team with robust engineering practices and reliability guarantees, I will feel the force that constantly pushes me out of this team – the “serious business” processes will aggravate the crap out of me.
Conversely, if I grew up in a large company where landing one CL a week was somewhat of an achievement, joining a small team of rapid prototypers may leave me in bewilderment: how dare these people throw code at the repo without any code reviews?! And why does it feel like everyone is zooming past me?
Similarly, every technology organization has a waterline. Everything above this waterline will move at a faster pace than the organization. Everything below will be slower.
If this organization decides to enter the game at the faster-pace layer, they will see themselves being constantly lapped: new, better products will emerge faster than the team can keep up with. We would be still in the planning stages of a new feature while another player at this layer already shipped several iterations of it.
Similarly, the organization will struggle applying itself effectively at the lower pace layers. We would ship a bunch of cool things, and see almost no uptick or change in adoption or usage patterns. Worse yet, our customers will complain of churn and instability, choosing more stable and consistent peers over us.
No matter how much we will want to play above or below our waterline, we’ll keep battling the force that nudges us toward us. We might speak passionately about needing to move faster and innovate, and be obsessed with speed as a concept – but if our team is designed to move at a deliberate pace of a tractor, all it will be is just talk.
When an organization is aware of its waterline, it can be very effective. Choosing to play only at the pace layer where the difference in relative velocity is minimal can be a source of a significant advantage in itself: the organization can apply itself fully to solving the problem at hand, rather than battling the invisible force that nudges it out of the pace layer it doesn’t belong to.
“Prepare for more tectonic shifts as the previously understood lines of the capacity limit are redrawn. Avoid early firm bets on the final shape of things in this space.” Those two sentences read like a horoscope 😂😂. Loved the idea of the information worker of the future as a reasoning network