
Week of 2023-05-15: Asymptotes and Value Niches + AI DX
Week of 2023-05-15: Asymptotes and Value Niches + AI DX

Where I learn about the new framing that seems to help explore a problem space and identify potential areas of focus, and then apply it to the nascent AI Developer Experience space.
Asymptotes and Value Niches
I have been thinking lately about a framing that would help clarify where to invest one’s energy while exploring a problem space. I realized that my previous writing about layering might come in handy.
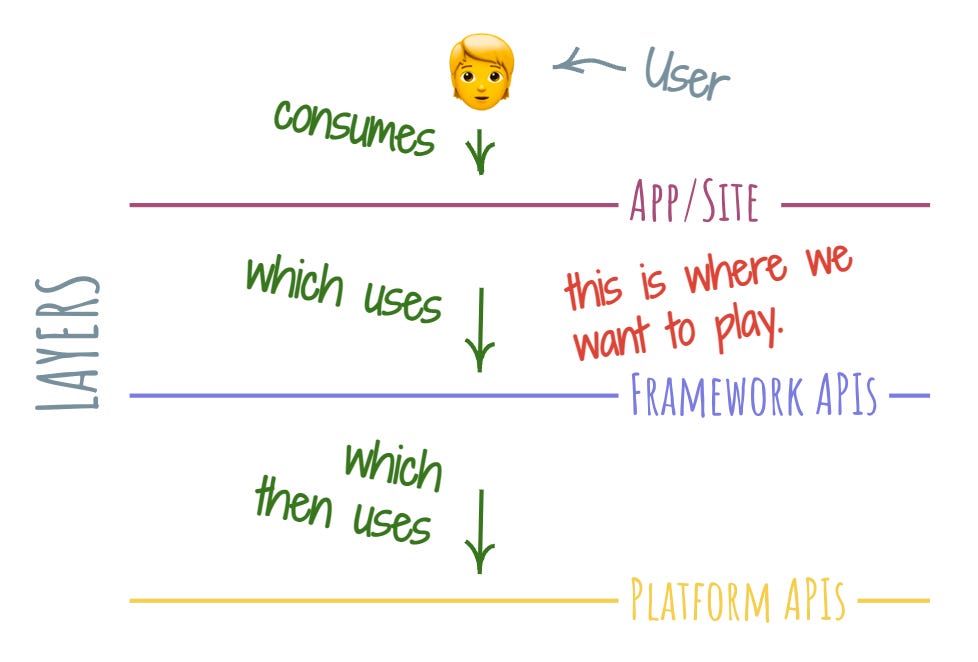
This framing might not work for problem spaces that aren’t easily viewed in terms of interactions between layers. However, if the problem space can be viewed in such a way, we can then view our investment of energy as an attempt to create a new layer on top of an existing one.
Typically, new layers tend to emerge to fill in the insufficient capabilities of the previous layers. Just like the jQuery library emerged to compensate for consistency in querying and manipulating the document object model (DOM) across various browsers, new layers tend to crop up where there’s a distinct need for them.
This happens because of the fairly common dynamic playing out at the lower layer: no matter how much we try, we can’t get the desired results out of the current capabilities of that layer. Because of this growing asymmetry of effort-to-outcome in the dynamic, I call it “the asymptote” – we keep trying harder, but get results that are about the same.
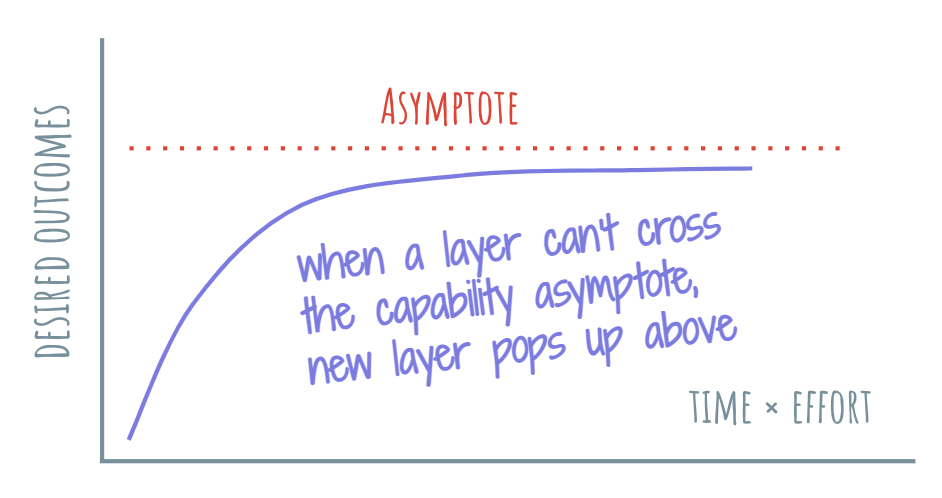
Asymptotes can be soft and firm.
Firm asymptotes typically have something to do with the laws of physics. They’re mostly impossible to get around. Moore’s law appears to have run into this asymptote as the size of a transistor could no longer get any smaller.
Soft asymptotes tend to be temporary and give after enough pressure is applied to them. They are felt as temporary barriers, limitations that are eventually overcome through research and development.
One way to look at the same Moore’s law is that while the size of the transistor has a firm asymptote, all the advances in hardware and software keep pushing the soft asymptote of the overall computational capacity forward.
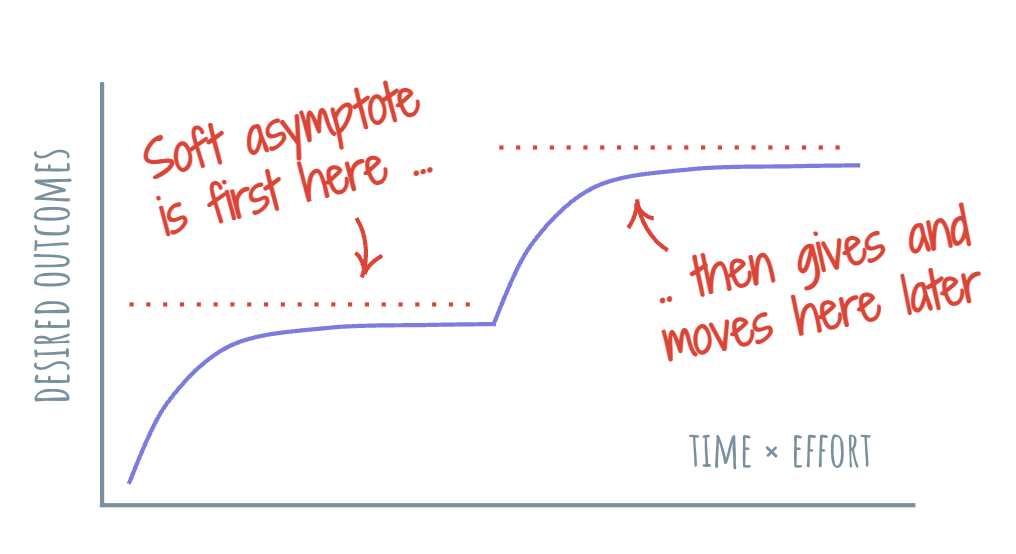
When we think about where to focus, asymptotes become a useful tool. Any asymmetry in effort-to-outcome is usually a place where a new layer of opinion will emerge. When there’s a need, there’s potential value to be realized by serving that need. There’s a potential value niche around every asymptote. The presence of an asymptote represents opportunities: needs that our potential customers would love us to address.
Depending on whether the asymptotes are soft or firm, the opportunities will look differently.
When the asymptote is firm, the layer that emerges on top becomes more or less permanent. These are great to build a solid product on, but are also usually subject to strong five-force dynamics. Many others will want to try to play there, so the threat of “race to the bottom” will be ever-present. However, if we’re prepared for the long slog and have the agility to make lateral moves, this could be a useful niche to play in.
The jQuery library is a great example here. It wasn’t the first or last contender to make life easier for Web developers. Among Web platform engineers, there was a running quip about a new Web framework or library being born every week. Yet, jQuery found its place and is still alive and kicking.
When the asymptote is soft, the layer we build will need to be more mercurial, forced to adapt and change as the asymptote is pushed forward with new capabilities from the lower layer. These new capabilities of the layer below could make our layer obsolete, irrelevant – and sometimes the opposite.
A good illustration of the latter is how the various attempts to compile C++ into Javascript were at best a nerdy oddity – until WebAssembly suddenly showed up as a Web platform primitive. Nerdy oddities quickly turned into essential tools of the emergent WASM stack.
Putting in sweat and tears around a soft asymptote usually brings more sweat and tears. But this investment might still be worth it if we have an intuition that we’ll hit the jackpot when the underlying layer changes again.
Having a keen intuition of how the asymptote will shift becomes important with soft asymptotes. When building around a soft asymptote, the trick is to look ahead to where it will shift, rather than grounding in its current state. We still might lose our investment if we guess the “where” wrong, but we’ll definitely lose it if we assume the asymptote won’t shift.
To bring this all together, here’s a recipe for mapping opportunities in a given problem space:
Orient yourself. Does the problem space look like layers? Try sketching out the layer that’s below you (“What are the tools and services that you’re planning to consume? Who are the vendors in your value chain?”), the layer where you want to build something, and the layer above where your future customers are.
Make a few guesses about the possible asymptotes. Talk to peers who are working in or around your chosen layer. Identify areas that appear to exhibit the diminishing returns dynamic. What part of the lower layer is in demand, but keeps bringing unsatisfying results? Map out those guesses into the landscape of asymptotes.
Evaluate firmness/softness of each asymptote. For firm asymptotes, estimate the amount of patience, grit, and commitment that will be needed for the long-term optimization of the niche. For soft asymptotes, see if you have any intuitions on when and how the next breakthrough will occur. Decide if this intuition is strong enough to warrant investment. Aim for the next position of the asymptote, not the current one.
At the very least, the output of this recipe can serve as fodder for a productive conversation about the potential problems we could collectively throw ourselves against.
🔗 https://glazkov.com/2023/05/17/asymptotes-and-value-niches/
AI Developer Experience Asymptotes
To make the asymptote and value niches framing a bit more concrete, let’s apply it to the most fun (at least for me) emergent new area of developer experience: the various developer tools and services that are cropping up around large language models (LLMs).
As the first step, let’s orient. The layer above us is AI application developers. These are folks who aren’t AI experts, but are instead experienced full-stack developers who know how to build apps. Because of all the tantalizing promise of something new and amazing, they are excited about applying the shiny new LLM goodness.
The layer below us is the LLM providers, who build, host, and serve the models. We are in the middle, the emerging connective tissue between the two layers. Alright – this looks very much like a nice layered setup!
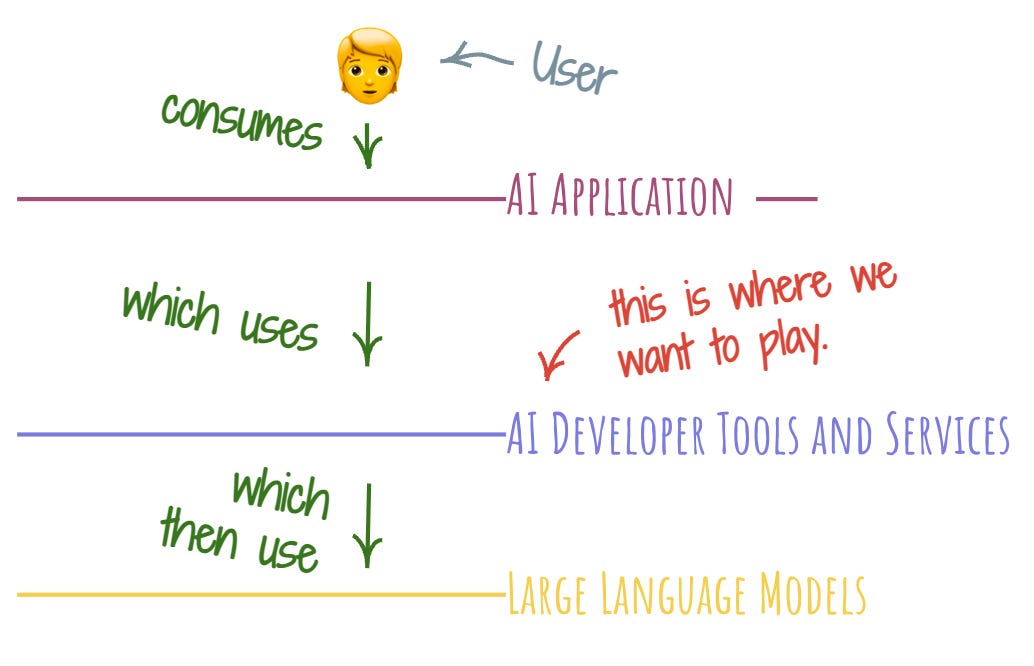
Below is my map of the asymptotes. This is not a complete list by any means, and it’s probably wrong. I bet you’ll have your own take on this. But for the purpose of exercising the asymptotes framing, it’ll do.

🚤 Performance
I will start with the easiest one. It’s actually several asymptotes bundled into one. Primarily because they are so tied together, it’s often difficult to tell which one we’re actually talking about. If you have a better way to untangle this knot, please go for it.
Cost of computation, latency, availability – all feature prominently in conversations with AI application developers. Folks are trying to work around all of them. Some are training smaller models to save costs. Some are sticking with cheaper models despite their more limited capabilities. Some are building elaborate fallback chains to mitigate LLM service interruptions. All of these represent opportunities for AI developer tooling. Anyone who can offer better-than-baseline performance will find a sound value niche.
Is this a firm asymptote or a soft one? My guess is that it’s fairly soft. LLM performance will continue to be a huge problem until, one day, it isn’t. All the compute shortages will continue to be a pain for a while, and then, almost without us noticing, they will just disappear, as the lower layers of the stack catch up with demand, reorient, optimized – in other words, do that thing they do.
If my guess is right, then if I were to invest around the performance asymptote, I would structure it in a way that would keep it relevant after the asymptote gives. For example, I would probably not make it my main investment. Rather, I would offer performance boosts as a complement to some other thing I am doing.
🔓 Agency
I struggled with naming this asymptote, because it is a bit too close to the wildly overused moniker of “Agents” that is floating around in AI applications space. But it still seems like the most appropriate one.
Alex Komoroske has an amazing framing around tools and services, and it describes the tension perfectly here. There is a desire for LLMs to be tools, not services, but the cost of making and serving a high-quality model is currently too high.
The agency asymptote clearly interplays with the performance asymptote, but I want to keep it distinct, because the motivations, while complementary, are different. When I have agency over LLMs, I can trace the boundary around it – what is owned by me, and what is not. I can create guarantees about how it’s used. I can elect to improve it, or even create a new one from scratch.
This is why we have a recent explosion of open source models, as well as the corresponding push to run models on actual user devices – like phones. There appears to be a lot of AI developer opportunities around this asymptote, from helping people serve their models to providing tools to train them.
Is this value niche permanent or temporary? I am just guessing here, but I suspect that it’s more or less permanent. No matter how low the costs and latency, there will be classes of use cases where agency always wins. My intuition is that this niche will get increasingly smaller as the performance asymptote gets pushed upward, but it will always remain. Unless of course, serving models becomes so inexpensive that they could be hosted from a toaster. Then it’s anyone’s guess.
💾 Memory
LLMs are weird beasts. If we do some first-degree sinning and pretend that LLMs are humans, we would notice that they have the long-term memory (the datasets on which they were trained) and the short-term memory (the context window), but no way to bridge the two. They’re like that character from Memento: know plenty of things, but can’t form new memories, and as soon as the context window is full, can’t remember anything else in the moment.
This is one of the most prominent capability asymptotes that’s given rise to the popularity of vector stores, tuning, and the relentless push to increase the size of the context window.
Everyone wants to figure out how to make an LLM have a real memory – or at least, the best possible approximation of it. If you’re building an AI application and haven’t encountered this problem, you’re probably not really building an AI application.
Based on how I see it, this is a massive value niche. Because of the current limitation of how the models are designed, something else has to compensate for its lack of this capability. I fully expect a lot of smart folks to continue to spend a lot of time trying to figure out the best memory prosthesis for LLMs.
What can we know about the firmness of this asymptote? Increasing the size of the context window might work. I want to see whether we’ll run into another feature of the human mind that we take for granted: separation between awareness and focus. A narrow context window neatly doubles as focus – “this is the thing to pay attention to”. I can’t wait to see and experiment with the longer context windows – will LLMs start experiencing the loss of focus as their awareness expands with the context window?
Overall, I would position the slider of the memory asymptote closer to “firm”. Until the next big breakthrough with LLM design properly bridges the capability gap, we’ll likely continue to struggle with this problem as AI application developers. Expect proliferation of tools that all try to fill this value niche, and a strong contentious dynamic between them.
📐 Precision
The gift and the curse of an LLM is the element of surprise. We never quite know what we’re going to get as the prediction plays out. This gives AI applications a fascinating quality: we can build a jaw-dropping, buzz-generating prototype with very little effort. It’s phenomenally easy to get to the 80% or even 90% of the final product.
However, eking out even a single additional percentage point comes at an increasingly high cost. The darned thing either keeps barfing in rare cases, or it is susceptible to trickery (and inevitable subsequent mockery), making it clearly unacceptable for production. Trying to connect the squishy, funky epistemological tangle that is an LLM to the precise world of business requirements is a fraught proposition – and thus, a looming asymptote.
If everyone wants to ship an AI application, but is facing the traversal of the “last mile” crevasse, there’s a large opportunity for a value niche around the precision asymptote.
There are already tools and services being built in this space, and I expect more to emerge as all those cool prototypes we’re all seeing on Twitter and Bluesky struggle to get to shipping. Especially with the rise of the agents, when we try to give LLMs access to more and more powerful capabilities, it seems that this asymptote will get even more prominent.
How firm is this asymptote? I believe that it depends on how the LLM is applied. The more precise the outcomes we need from the LLM, the more challenging they will be to attain. For example, for some use cases, it might be okay – or even a feature! – for an LLM to hallucinate. Products built to serve these use cases will feel very little of this asymptote.
On the other hand, if the use case requires an LLM to act in an exact manner with severe downside of not doing so, we will experience precision asymptote in spades. We will desperately look for someone to offer tools or services that provide guardrails and telemetry to keep the unruly LLM in check, and seek security and safety solutions to reduce abuse and incursion incidents.
I have very little confidence in a technological breakthrough that will significantly alleviate this asymptote.
🧠 Reasoning
One of the key flaws in confusing what LLMs do with what humans do comes from the underlying assumption that thinking is writing. Unfortunately, it’s the other way around. Human brains appear to be multiplexed cognition systems. What we presume to be a linear process is actually an emergent outcome within a large network of semi-autonomous units that comprise our mind. Approximating thinking and reasoning as spoken language is a grand simplification – as our forays into using LLMs as chatbots so helpfully point out.
As we try to get the LLMs to think more clearly and more thoroughly, the reasoning asymptote begins to show up. Pretty much everyone I know who’s playing with LLMs is no longer using just one prompt. There are chains of prompts and nascent networks of prompts being wired to create a slightly better approximation of the reasoning process. You’ve heard me talk about reasoning boxes, so clearly I am loving all this energy, and it feels like stepping toward reasoning.
So far, all of this work happens on top of the LLMs, trying to frame the reasoning and introduce a semblance of causal theory. To me, this feels like a prime opportunity at the developer tooling layer.
This asymptote also seems fairly firm, primarily because of the nature of the LLM design. It would take something fundamentally different to produce a mind-like cognition system. I would guess that, unless such a breakthrough is made, we will see a steady demand and a well-formed value niche for tools that help arrange prompts into graphs of flows between them. I could be completely wrong, but if that’s the case, I would also expect the products that aids in creating and hosting these graphs will be the emergent next layer in the LLM space, and many (most?) developers will be accessing LLMs through these products. Just like what happened with jQuery.
There are probably several different ways to look at this AI developer experience space, but I hope this map gives you: a) a sense of how to apply the asymptotes and value niches framing to your problem space and b) a quick lay of the land of where I think this particular space is heading.